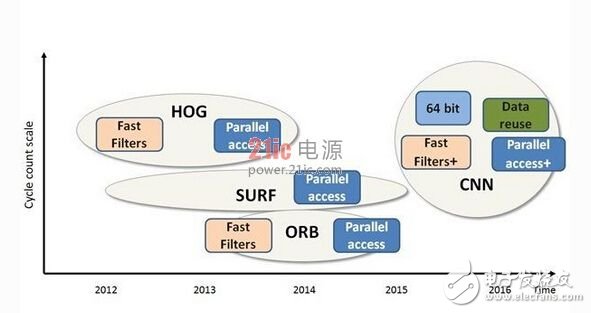
Target detection and recognition is an integral part of computer vision systems. In computer vision, the first is to decompose the scene into components that the computer can see and analyze. The first step in computer vision is feature extraction, which detects key points in an image and obtains meaningful information about those key points. The feature extraction process itself consists of four basic phases: image preparation, keypoint detection, descriptor generation, and classification. In fact, this process checks each pixel to see if any features are present in the pixel. A feature extraction algorithm describes an image as a set of feature vectors that point to key elements in the image. This article will review a series of feature detection algorithms, in this process, to see how the general target recognition and specific feature recognition have evolved over the years. Early feature detector Scale Invariant Feature Transform (SIFT) and Good Features To Track (GFTT) are early implementations of feature extraction techniques. But these are computationally intensive algorithms that involve a large number of floating point operations, so they are not suitable for real-time embedded platforms. Taking SIFT as an example, this high-precision algorithm can produce good results in many cases. It looks for features with sub-pixel precision, but only features that are similar to corners. Moreover, although SIFT is very accurate, it is complex to implement in real time and often uses a lower input image resolution. SIFT is a computationally intensive algorithm Therefore, SIFT is not commonly used at present, and it is mainly used as a reference to measure the quality of the new algorithm. Because of the need to reduce the computational complexity, it eventually led to the development of a new feature extraction algorithm that is easier to implement. Second generation algorithm Speeded Up Robust Features (SURF) was one of the first feature detectors to consider efficiency. It replaces the voluminous operations in SIFT with a series of additions and subtractions in different rectangular sizes. Moreover, these operations are easy to vectorize and require less memory. Next, Histograms of Oriented Gradients (HOG), a popular pedestrian detection algorithm commonly used in the automotive industry, can be varied, using different scales to detect objects of different sizes, and using the amount of overlap between blocks to improve the quality of detection, and Does not increase the amount of calculation. It can take advantage of parallel memory access instead of processing only one lookup table at a time, as in traditional storage systems, thus speeding up the lookup based on the parallelism of memory. Then, Oriented FAST and Rotated BRIEF (ORB), an efficient algorithm used to replace SIFT, will use binary descriptors to extract features. The ORB combines the increase in direction with the FAST corner detector and rotates the BRIEF descriptor to align it with the angular direction. Binary descriptors combined with lightweight functions such as FAST and Harris Corner produce a very computationally efficient and fairly accurate description. Highly computationally efficient algorithms such as SURF and ORB provide the possibility to implement a more powerful framework such as CNN CNN: The next frontier of embedded platform target recognition Smart cameras with smartphones, tablets, wearables, surveillance systems and automotive systems bring the industry to a crossroads, requiring more advanced algorithms for compute-intensive applications, providing more Environmentally intelligent user experience. Therefore, the computational complexity needs to be reduced again to accommodate the stringent requirements of powerful algorithms used in these mobile and embedded devices. Inevitably, the need for higher precision and more flexible algorithms will lead to vector accelerated depth learning algorithms, such as convolutional neural networks (CNN), for classifying, locating, and detecting targets in images. For example, in the case of traffic sign recognition, the CNN-based algorithm outperforms all current target detection algorithms in recognition accuracy. In addition to high quality, CNN's main advantage over traditional target detection algorithms is that CNN's adaptive ability is very strong. It can be quickly "tuned" to accommodate new goals without changing the algorithm code. Therefore, CNN and other deep learning algorithms will become mainstream target detection methods in the near future. CNN has very demanding computing requirements for mobile and embedded devices. Convolution is a major part of CNN calculations. CNN's 2D convolutional layer allows users to increase processing efficiency by performing overlapping convolutions by simultaneously executing one or more filters on the same input. So, for embedded platforms, designers should be able to perform convolution very efficiently to take full advantage of CNN streams. In fact, CNN is not strictly an algorithm, but an implementation framework. It allows users to optimize basic building blocks and build an efficient neural network detection application. Because the CNN framework computes each pixel one by one, and pixel-by-pixel computing is a very demanding operation, it requires more computation. Unremittingly improving the vision processor CEVA has found two other ways to increase computational efficiency while still continuing to develop algorithms that will be adopted, such as CNN. The first is a parallel random memory access mechanism that supports multi-scalar functionality, allowing vector processors to manage parallel load capabilities. The second is the sliding window mechanism, which improves data utilization and prevents the same data from being repeatedly loaded multiple times. Most imaging filters and large input frame convolutions have a large amount of data overlap. This data overlap increases as the vectorization of the processor increases, which can be used to reduce data traffic between the processor and the memory, thereby reducing power consumption. This mechanism exploits large-scale data overlap, allowing developers to freely implement efficient convolution in deep learning algorithms, which typically results in extremely high utilization of DSP MAC operations. The deep learning algorithm for target recognition once again raises the threshold for computational complexity, so a new type of intelligent vision processor is needed that should improve processing efficiency and accuracy to meet the challenges. CEVA-XM4-CEVA's latest vision and imaging platform, combined with vision algorithm expertise and processor architecture technology, provides a well-designed vision processor to address the challenges of embedded computer vision. Multifunctional High Speed Blender,Mute Wall High Speed Blenders,Household High-Speed Blender,Good High Speed Blender JOYOUNG COMPANY LIMITED , https://www.globaljoyoung.com